
1 HUMANS AT THE CENTER STAGE
1.1 Understanding the human body and activities
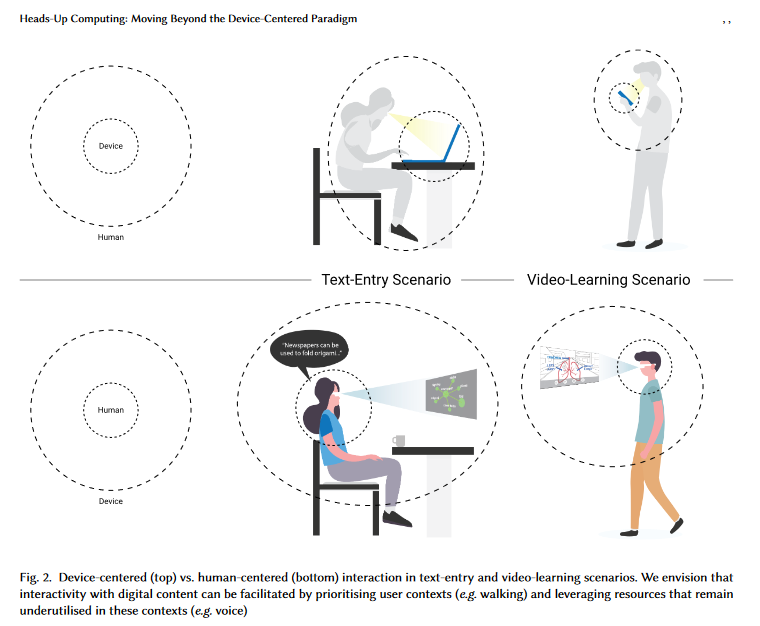
The human body comprises both input and output (I/O) channels to perceive the world around us. Common human-computer interactions involve the use of our hands to click on a mouse or tap a phone screen, or our eyes to read from a computer screen. However, the hands and eyes are also essential for performing daily activities such as cooking and exercising. When device interactions are performed simultaneously with these primary tasks, competition for I/O resources is introduced [24]. As a result, current computing activities are performed either separately from our daily activities (e.g. work in an office, live elsewhere) or in an awkward combination (e.g. typing and walking like a smartphone zombie). While effective support of multitasking is a complex topic, and in many cases, not possible, computing activities can still be more seamlessly integrated with our daily lives if the tools are designed using a human-centric approach. By carefully considering resource availability, i.e. the amount of resources available for each I/O channel in the context of the user’s environment and activity, devices could better distribute task loads by leveraging underutilized natural resources and lessening the load on overutilized modalities. This is especially true for scenarios involving so-called multi-channel multitasking [ 8]: in which one of the task is largely automatic (e.g. routine manual tasks such as walking, washing dishes, etc.).
To design for realistic scenarios, we look into Dollar [6]’s categorization of Activities of Daily Living (ADL), which provides a taxonomy of crucial daily tasks (albeit originally created for older adults and rehabilitating patients). The ADL
categories range from domestic (e.g. office presentation), extradomestic (e.g. shopping), and physical self-maintenance (e.g. eating), providing sufficient representation of what the general population engages in every day. It is helpful to select examples from this broad range of activities when learning about resource demands. We can analyze an example activity for its hands- and eyes-busy nature, identify underutilized/overutilized resources, then select opportunistic
moments for the system to interact with the user. For example, where the primary activity requires the use of hands but not the mouth and ears (e.g. when a person is doing laundry), it may be more appropriate for the computing system to prompt the user to reply to a chat message via voice instead of thumb-typing. But if the secondary task requires a significant mental load, e.g. composing a project report, the availability of alternative resources may not be sufficient to support multitasking. Thus, it is important to identify secondary tasks that not only can be facilitated by underutilised resources, but also minimal overall cognitive load that are complementary to the primary tasks.
To effectively manage resources for activities of daily living and digital interactions, we refer to the theory of multitasking. According to Salvucci et al. [30], multitasking involves several core components (ACT-R cognitive architecture, threaded cognition theory, and memory-for-goals theory). Multiple tasks may appear concurrently or
sequentially, depending on the amount of time a person spends on one task before switching to another. For concurrent multitasking, tasks are harder to perform when they require the same resources. They are easier to implement if multiple resource types are available [37]. In the case of sequential multitasking, users switch back and forth between the primary and secondary tasks over a longer period of time (minutes to hours). Reducing switching costs and facilitating the rehearsal of the ‘problem representation’ [ 1] can significantly improve multitasking performance. Heads-Up computing is explicitly designed to take advantage of these theoretical insights: 1) its voice + subtle gesture interaction method relies on available resources during daily activities; 2) its heads-up optical head-mounted see-through display (OHMD)
also facilitates quicker visual attention switches.
Overall, we envision a more seamless integration of devices into human life by first considering the human’s resource availability, primary/ secondary task requirements, then resource allocation.
3 A DAY IN THE LIFE WITH HEADS-UP COMPUTING
Beth is a mother of two who works from home. She starts her day by preparing breakfast for the family. Today, she sets out to cook a new dish, the broccoli frittata. With the help of a Heads-Up computing virtual assistant named Tom, Beth voices out, “Hey Tom, what are the ingredients for broccoli frittata?” Tom renders an ingredient checklist on Beth’s smart glasses. Through the smart glasses’ front camera, Tom sees what Beth sees, and detects that she is scanning the fridge. This intelligent sensing prompts Tom to update the checklist collaboratively with Beth as she removes
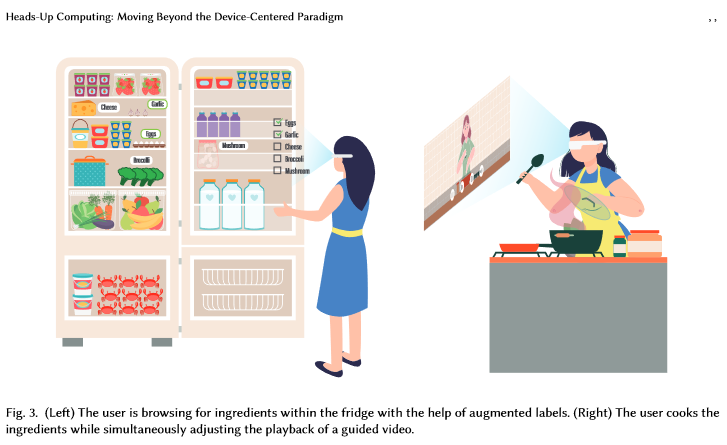
each ingredient from the fridge and places it on the countertop, occasionally glancing at her see-through display to double-check that each item matches. With advanced computer vision and Augmented Reality (AR) capabilities, Beth can even request Tom to annotate where each ingredient is located within her sight. Once all the ingredients have been identified, Beth proceeds with the cooking. Hoping to be guided with step-by-step instructions, she speaks out: “Hey Tom, show me how to cook the ingredients.” Tom searches for the relevant video on YouTube and automatically cuts it into step-wise segments, playing the audio through the wireless earset and video through the display. Beth toggles the ring mouse she is wearing to jump forward or backward from the video. Despite requiring both hands for cooking,
she can utilize her idle thumb to control the playback of the video tutorial simultaneously. Tom’s in-time assistance seamlessly adapts to Beth’s dynamic needs and constraints without referring to her remote phone, which would pause her task progress.
Beth finishes with the cooking and feeds her kids, during which she receives an email from her work supervisor, asking for her available timing for an emergency meeting. Based on Beth’s previous preferences, Tom understands that Beth values quality time with her family and prevents her from being bombarded by notifications from work or social groups during certain times of the day. However, she makes an exception for messages labeled as ‘emergency.’ Like an intelligent observer, Tom adjusts information delivery to Beth by saying, “You have just received an emergency email from George Mason. Would you like me to read it out?”. Beth can easily vocalize “Yes” or “No” based on what suits her. By leveraging the idle ears and mouth, Heads-Up computing allows Beth to focus her eyes and hands on what matters
more in that context: her family.
Existing voice assistants such as Amazon Alexa, Google Assistant, Siri from Apple, and Samsung Bixby have gained worldwide popularity for the conversational interaction style that they offer. They can be defined as “software agents that are powered by artificial intelligence and assist people with information searches, decision-making efforts or executing certain tasks using natural language in a spoken format” [ 15 ]. Despite allowing users to multitask and work hands-free, the usability of current speech-based systems still varies greatly [ 40 ]. These voice assistants currently do not achieve the depth of personalization and integration that Heads-Up computing can achieve given its narrower focus on the users’ immediate perceptual space and a clearly defined form i.e. hardware and software.
The story above depicts a system that leverages visual, auditory, and movement-based data from a distributed range of sensors on the user’s body. It adopts a first-person view as it collects and analyzes contextual information (e.g. the camera on the glasses sees what the user sees and the microphone on the headpiece hears what the user hears). It leverages the resource-aware interaction model to optimize the allocation of Beth’s bodily resources based on the constraints of her activities. The relevance and richness of data collected from the user’s immediate environment, coupled with the processing capability, allows the system to anticipate and to calculate quantitative information ahead of the user. Overall, we envision that Tom will be a human-like agent, able to interact with and assist humans. From cooking to commuting, we believe that providing just-in-time assistance has the potential to transform relationships between devices and humans, thereby improving the way we live, learn, work, and play.


Notifications
Present notifications effectively on OHMD to minimize distractions to primary tasks (e.g. notification display for conversational settings)

Resource interaction model
Establish how different situations affect our ability to in-take information on different input channels. Understand what input methods are comfortable and non-intrusive to users’ everyday tasks.

Monitoring Attention
Monitor attention state fluctuations continuously and reliably via EEGs (e.g. during video-learning scenarios)

Education & Learning
Design learning videos on OHMD for on-the-go situations, effectively distributing users’ attention between learning and walking tasks. Support microlearning in mobile scenarios (mobile information acquisition).

Healthcare & Wellness
Facilitate OHMD-based mindfulness practice that is highly accessible, convenient, and easy for novice practitioners to implement in casual everyday settings

Text Presentation
Explore text display design factors for optimal information consumption on OHMDs (e.g. in mobile environments)

Developer/Research tools for Heads-Up applications
Provide testing and development tools to help researchers and developers build Heads-Up applications, streamlining their work process (e.g. learning video-builder)












